Cath wants to say: The comments and follow up posts on LessWrong are very helpful and provide additional context.
Link: https://www.alignmentforum.org/s/h95ayYYwMebGEYN5y
Summary from original post: This post introduces causal scrubbing, a principled approach for evaluating the quality of mechanistic interpretations. The key idea behind causal scrubbing is to test interpretability hypotheses via behavior-preserving resampling ablations. We apply this method to develop a refined understanding of how a small language model implements induction and how an algorithmic model correctly classifies if a sequence of parentheses is balanced.
Introduction
- The methods used to evaluate the quality of interpretations is largely ad hoc, thus posing a problem for scaling up.
- CaSc is an attempt to automatically check the correctness of interpretations instead of relying on intuition/researchers.
- CaSc is a systemic ablation method for testing interpretability hypotheses about how a NN implements a behaviour on a dataset
- We convert these hypotheses into a formal correspondence between a graph for the model and a graph for a human
- CaSc starts from the output and recursively finds all invariances of parts of the NN that are implied by the hypotheses, replaces these activations with the maximum entropy (noisy) distribution. Then we measure how well the scrubbed model implements the same behaviour.
- If the hypotheses is correct, then the scrubbed model should implement the behaviour as well as the unscrubbed model.
- Applications:
- CaSc should work on most (if not all) interp hypotheses
- We might be able to use CaSc to “narrow” our claims or make hypotheses
Causal Scrubbing
- Assume a dataset D over domain X and a function f(X) → R
- We explain E(f(X))
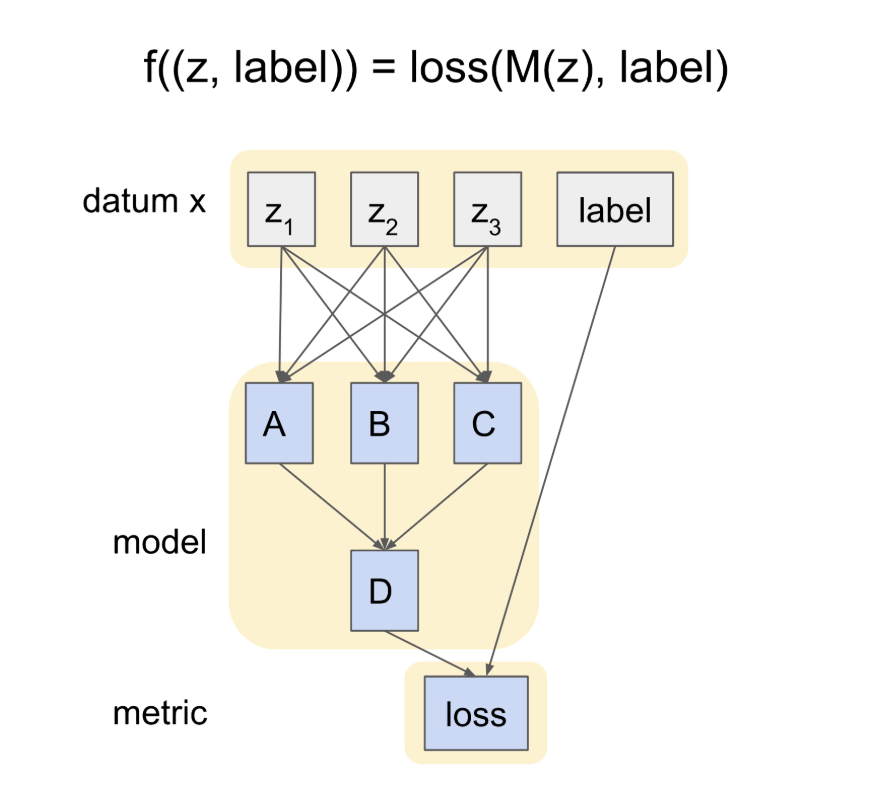
- Example: Explaining Induction Heads. Your dataset would have datums with prompt “…AB …A”, and you would expect output “B”
- An interp hypothesis h for the function f can be formalised as a three-tuple (G, I, c)
- G is a computational graph for the model which implements the function f
- Therefore, G should be extensionally equal to f on all of domain X
- I is a computational graph for the human to interpret. It acts as a heuristic.
- c is a correspondence function from the nodes of I to the nodes of G (such that the human can interpret what the model has implemented)
- I and G should have a single input and output nodes, which are of type X.
- G is a computational graph for the model which implements the function f
An example hypothesis:
- Through some mech interp testing, we might think that the way G works is that A computes whether z1 > 3, and B computes whether z2 > 3. A and B then feed into D, which is an OR function on the truth value of A or B. The behaviour might then be explained through the relationship between D and the true label y such that output = D == y.
- So I is a heuristic of the model our mech interp research hypothesises.
- Note that c (which maps from an I node to a G node), does not tell you how to translate a value of I into an activation of G.
- c(I) are the “important nodes” of G
- let n_I and n_G be nodes in I, G, then c(n_I) = n_G
- Although the paper tests a weaker claim that requires the equivalence classes on inputs of n_I to be equal to the equivalnce classes on inputs to n_G.
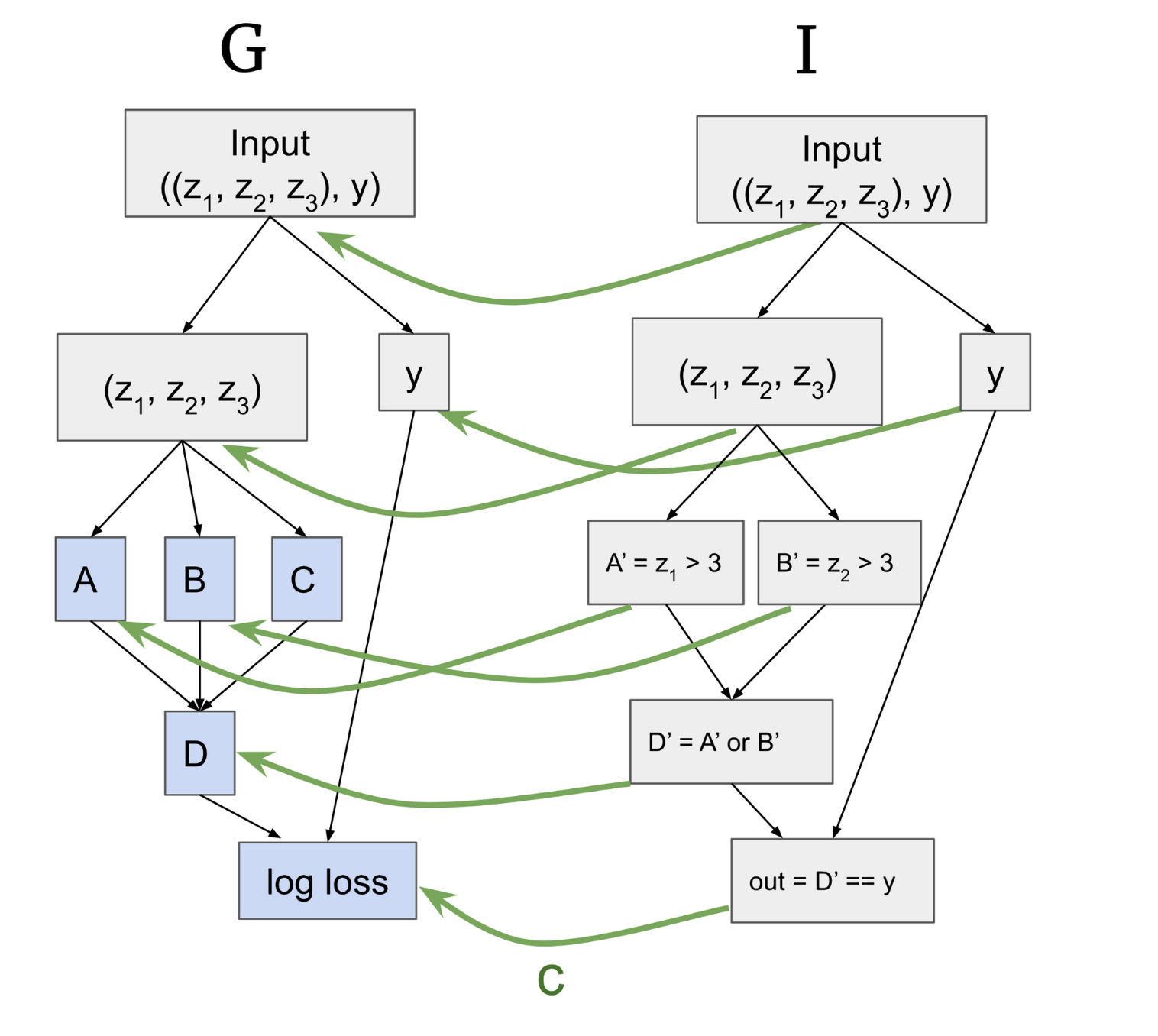
Replacing activations: (c) maps to the nodes of G highlighted in green. In other words, they are the nodes that we think are “useful” or involved in producing a result.
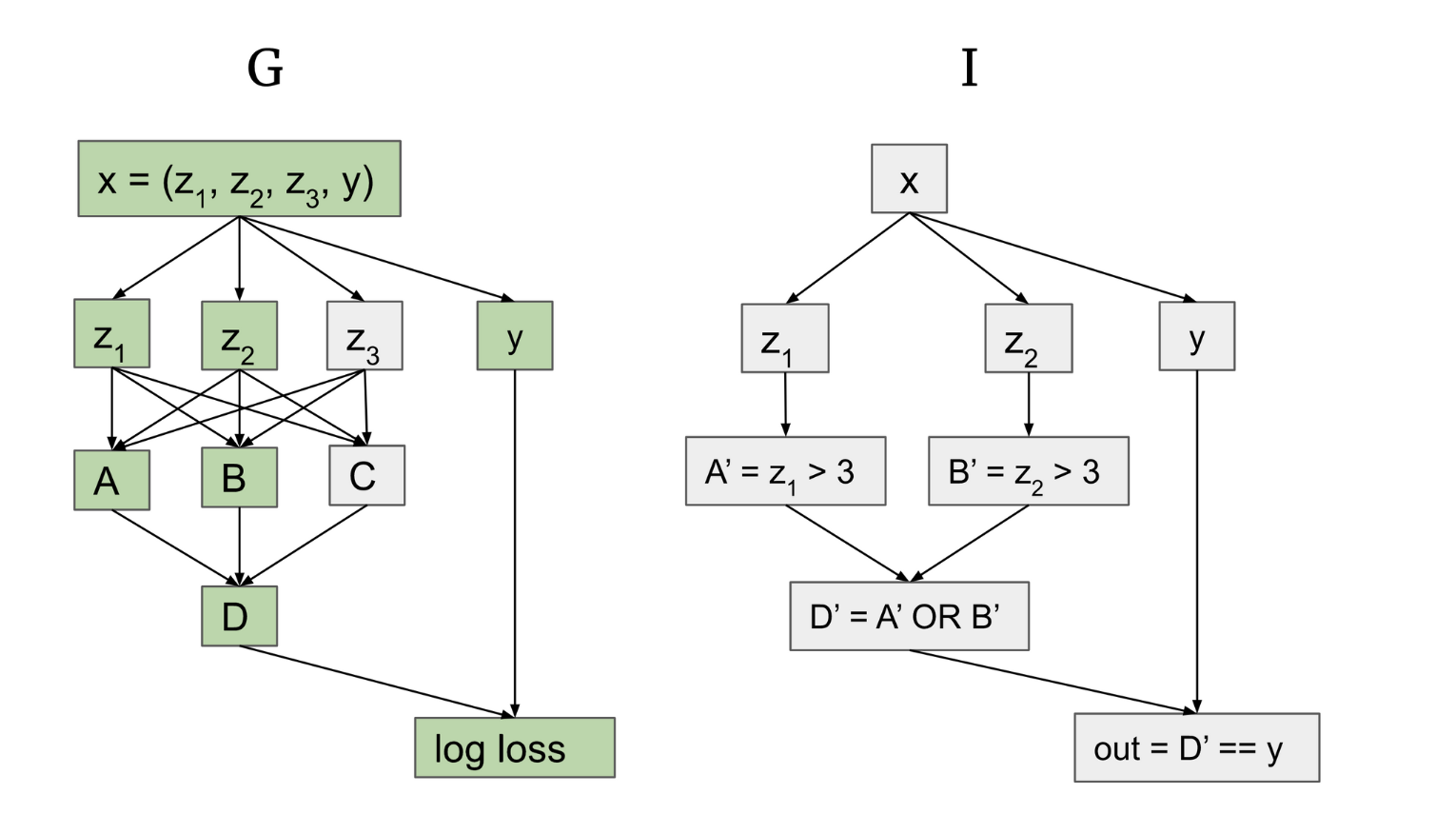
- If I’s interpretation is true, we should be able to perform two resampling ablations.
- We replace the activations of A, B, D (the important nodes) with activations on other inputs that are “equivalent” in I
- We replace the activations of C or unimportant paths with activations of any other input that are “equivalent” on I.
- Replacing an activation with an activation from a different input is equivalent to replacing all inputs in the subtree upstream of that activation.
See section 3.1 of the original post for more detail on the two types of ablations/interventions and tree diagrams that can help you visualise the ablations better. They explained it pretty clearly.
Essentially, we can either show that an important node is what causes the behaviour of a model by creating semantically equivalent “subtrees”. Or, we can verify that unimportant nodes are indeed unrelated to a model’s behaviour by arbitrarily resampling its inputs.
CaSc Algorithm
See section 3.1 of the original post for the actual pseudocode. I think it is helpful for me just to understand it intuitively.
Big picture-y stuff:
- A mech interp hypothesis says, everything in A is what causes this thing X in the model to happen. Everything in B is what doesn’t cause this thing X in the model to happen. You can test me by proving that everything in A is individually necessary and jointly sufficient to create X, and showing that nothing in B is necessary or sufficient to create X.
- Whenever we need to compute an activation, we look at all the other activations that we could replace that activation with, and see if it still preserves X.
- The scrubbed expectation is E_scrubbed(h, D), where h is the hypothesis and D is the domain.
The algorithm:
- First, we sample a random inference input x from domain D
- We traverse all paths (like the trees in the diagram) through I from the output towards the input. We use some function
run_scrubon each node of I recursively.- For each node, we consider everything upstream of n_I in I, which corresponds to everything upstream of n_G.
run_scrubshould take in argumentsn_I, c, D, xand return an activation from G (which makes sense, since c maps everything from I to G). More intuitively, the activation from G is what the hypothesis says should represent the value of n_I when I is run on x.- n_G = c(n_I)
- n_G returns x
- Important parent nodes:
- Determine the activations of each input from the parents of n_G, since the value of the parent is important for n_G.
- We select an input
new_xwhich agrees with x on the value of p1. In other words, it is semantically equivalent. - Call run_scrub on the parent to get a scrubbed activation for
new_x.
- Unimportant parent nodes:
- We select a random, noisy input
other_xfrom the dataset. The same random input should be used by all unimportant parents of a node (why do we use the same random input? The appendices say it creates an unambiguity). - Record pG on
other_xand get the scrubbed activations.
- We select a random, noisy input
- This algorithm should give us the activations of all the parents of n_G, which are the inputs to run the function for node n_G.
- Define another function called
sample_agreeing_xand return the output.
This algorithm looks to be pretty hard to implement.
Results
Results 1: Here are the detailed results of this algorithm when run on a small transformer which classifies sequences of parentheses as balanced or unbalanced.
Essentially, causal scrubbing shows that our mech interp hypothesis on how this transformer works is reasonable, but not completely accurate. The more specific our hypotheses are, the more they induce activation replacements which are deeper in the layers. Chan et al shows that their mech interp hypothesis was “subtly incorrect”, either missing pathways or imperfectly identifying features that the model uses.
Results 2: Here are the results of this algorithm when run on a 2-layer attention only model identifying induction heads.
Their hypothesis only explains 35% of the performance of the transformer. After edits to the hypothesis (changing the Q and V dependencies, allowing the attention pattern to compare a set of 3 consecutive tokens instead of 1, etc), the hypothesis was able to recover 86% of the transformer’s performance.
According to Buck Shlegeris, the causal scrubbing post contributed to Redwood abandoning some mech interp research in the future. Skimming through the appendices and the comments/discussions by authors helped me greatly. This paper also contributed to some of the discussion on whether mech interp is useful.