Cath wants to say: I only focused on the induction head part, since I think its the most valuable part of the paper to me, and I’m not very keen on explaining transformer circuits. I would like to come back later and finish the OV/QK circuits.
Link: https://transformer-circuits.pub/2021/framework/index.html
Induction Heads
Given a sentence:
Jack and Jill went up the hill. Jack gave some water to …
We want the model to predict the token “Jill”.
We can generalise this sentence structure in the form (A)(B) … (A) → predict (B). When a two names A and B are seen in close proximity together, it makes sense that the model should predict B when A is mentioned followed by a conjunction indicating a relationship between two people.
Elhage et al discovered the existence of induction heads, circuits that predict (B) when (A) precedes it to “complete the pattern”.
More on the structure of induction heads:
- Induction heads in their toy model (2 layer attention-only) are a circuit of two attention heads. The first head tells you the answer to “what is the previous token?“. The second head, which does most of the induction work, uses information from the first head to find tokens preceded by the present token (thus returning B).
- This means that induction heads show up in minimum 2-layer transformers. One layer models can do copying by repeating the first token they saw: (A)…(B) → (A)
- Elhage et al were able to show that induction heads implement a pattern copying behaviour and appear to be the primary source of in-context learning.
A more intuitive way an induction head works:
I want to predict what the next token after (A) is. Did I also see (A) previously? Yes, I did see (A) before. What token came after (A) the last time I saw (A)? Last time, (B) came after (A). My best guess is to predict that the next token is (B)
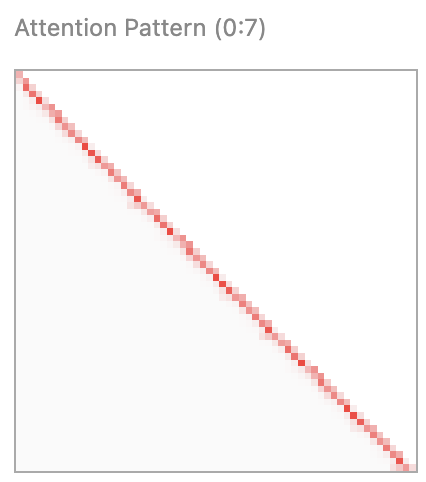
This is why attention patterns of induction heads look like the graph below. Later tokens are paying attention to what similar tokens came before (“Have I seen (A) before?“)
 Then, the induction head goes to the instance of the same token that occurred before, and asks that token “What comes after you?“. These attention heads will be a diagonal shifted down, because a token pays attention to the token coming directly after it.
Then, the induction head goes to the instance of the same token that occurred before, and asks that token “What comes after you?“. These attention heads will be a diagonal shifted down, because a token pays attention to the token coming directly after it.
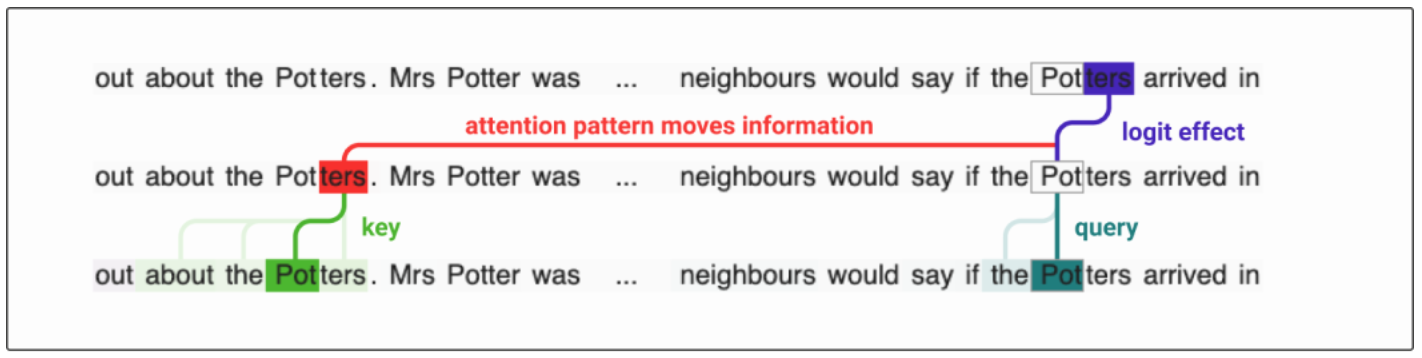
 Let the structure be (A1)(B1)…(A2) → predict (B2). The minimal way of creating an induction head is to use K-composition with a previous token head, shifting the key vector forward by one token.
Let the structure be (A1)(B1)…(A2) → predict (B2). The minimal way of creating an induction head is to use K-composition with a previous token head, shifting the key vector forward by one token.
(A2) uses the induction head and sends a query back to (A1), asking whether another instance of the token A has occurred. (A1)‘s key to (A2) says, “I can tell you that I occurred here before and I am the same token as you. I can answer your query”.
(A1) then uses the “next token” head and queries, “what token comes after me?” (B1) responds to the query: “I can answer your query.” (B1) sends the value back and tells (A1) that (B1) is the token after (A1). (A1) takes this information and sends it to (A2), telling (A2) that (B1) comes after (A1).
(A2) uses this information to predict (B2) through the logit effect.
The OV circuit should have a “copying” effect, and the QK circuit should be Id * A^h-1 * W, since W matches cases where the tokens are the same for attention scores for the previous token.