Link: https://transformer-circuits.pub/2023/monosemantic-features/index.html
Summary: Using a sparse autoencoder, we extract a large number of interpretable features from a one-layer transformer.
Cath wants to say: This summary will help you the most if you are reading the paper alongside and exploring the data visualisations for the A/1 interfact. Also, the results section for the Arabic and Hebrew features is quite interesting.
Introduction
-
Neurons in NNs are polysemantic - they can respond to many unrelated inputs. This makes it harder for us to reason about the behaviour of networks in terms of individual neurons.
- E.g. a neuron may respond to cats legs, cars, and palm trees, whereas we may hope for/expect there to be a neuron just for cat-related things.
-
A cause of polysemanticity is superposition, where a NN represents more independent “features” of the data than there are neurons by assigning each feature its own linear combination of neurons.
- I think of a feature as anything worth noting about the dataset, but Bricken et al describe it as “a ‘basic set’ of meaningful directions which more complex directions can be created from”. Hopefully one of those two intuitions makes sense to you.
-
If each feature can be represented by a vector, then the set of all features form an overcomplete linear basis for the activations of neurons.
-
“Toy Models of Superposition” shows that superposition can arise naturally during training if the set of features useful to a model are sparse in the training data.
- Sparsity allows a model to differentiate which combination of features produced an activation vector of a neuron.
-
We can find sparse and interpretable features if there are hidden/“cached” through superposition.
- We could create models without superposition, perhaps by encouraging activation sparsity
- Bricken et al eventually found this to be insufficient to prevent polysemanticity.
- We could use dictionary learning to find an overcomplete feature basis in a model which has superposition.
- Bricken et al found that this leads to overfitting.
- We could create models without superposition, perhaps by encouraging activation sparsity
-
So we use a hybrid approach: a “weak” dictionary learning algorithm called a sparse autoencoder. This will generate learned features from a model, which would give us more room for monosemanticity compared to the model’s neurons.
-
Turns out, the sparse autoencoder can extract interpretable (monosemantic) features from superposition and allow for simple circuit analysis.
-
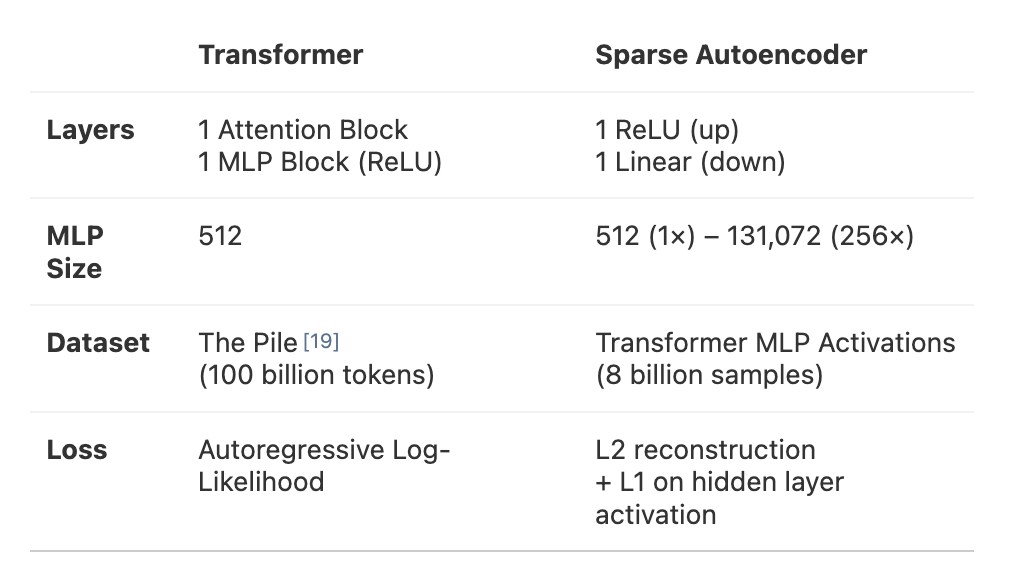
Methodology: A 1-layer transformer, 512-neuron MLP layer.
-
Goal: Decompose MLP activations into interpretable features by training sparse autoencoders on MLP activations from 8bi data points.
-
Yields: 90 learned dictionaries, extracted 4096 features from a run called A/1 and 512 features from a run called A/0 mapped onto different clusters.
- The data visualisation is very pretty and intuitive, I would highly recommend exploring.
-
Results summary are in the paper. Essentially, this confirmed their hypothesis in “Toy Models of Superposition”. The biggest finding is that sparse autoencoders can extract relatively monosemantic features which are otherwise invisible in individual neurons.
The superposition problem and set up
The sparse autoencoder works in the MLP layer in the activations, before ReLU.
 Set up of the sparse autoencoder:
Set up of the sparse autoencoder:
 Working through the set up intuition:
Working through the set up intuition:
- The goal of the sparse autoencoder is to decompose the MLP activations into interpretable monosemantic features.
- The activation vector can be decomposed into a combination of general vectors (for multiple features), which can be any direction.
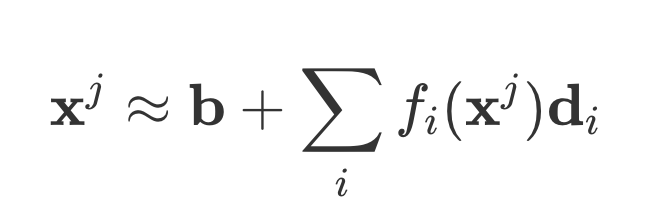
- x^j is the activation vector for datapoint j. f_i(x^j) is the activation of feature i. d_i is a unit vector in “activation space” which represents the direction feature i is super-positioned. b is an arbitrary bias.
- This is a commonly employed type of linear matrix factorisation in dictionary learning.
- The activation of a feature, f_i(x), are the output of the encoder. So, you should ReLU it.
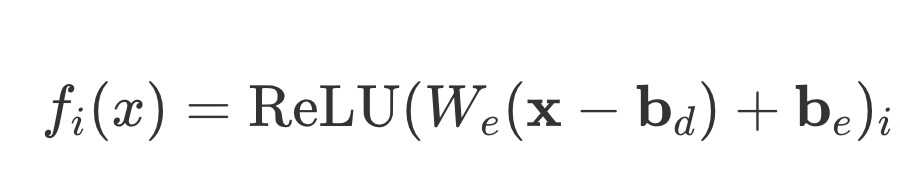
- W_e is the weight matrix of the encoder. b_d is the pre-encoder bas, and b_e is the encoder bias. b_d is affected by the encoder weights W_e.
So, doing a ReLU makes sense. T he features should form an overcomplete linear basis, so you want to perform a linear transformation. I could be wrong.
- Overcomplete just means that the decomposition has more directions d_i than neurons, which makes sense.
- The overcomplete basis is also why we could expand to have 256 times more features than neurons, hence the MLP size on the graph.
- Why 256? I’m not too sure.
Since the autoencoder takes in MLP activations, that is the dataset we sample from.
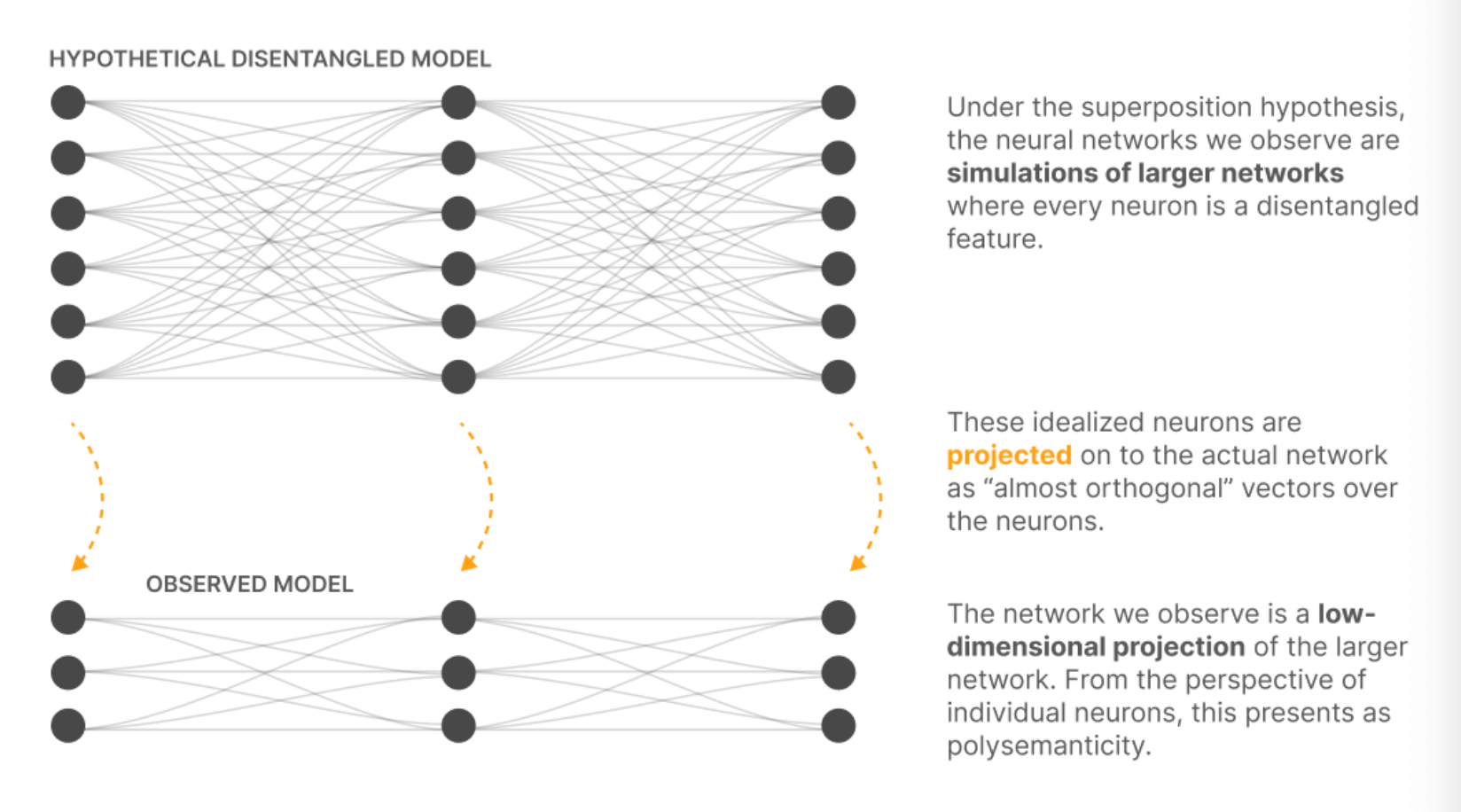
Superposition:
Here is a nice graph from the paper that explains the projection from high dimensionality “idealised” or “simulated” NNs, to the low-dimension, polysemantic NN.
- The L1 penalty on hidden layer activation encourages sparsity.
Interesting findings
- Training the autoencoder on more data makes the features “shaper” (perhaps more specific) and more interpretable.
- Over the course of training, some neurons would cease to activate. Resampling these dead neurons gives you better results, since the model can represent more features for a hidden layer dimension.
- It is harder than expected to tell whether the autoencoder is working, since you can’t use ablation. They used a combination of 4 metrics (manual inspection, feature density, loss, toy model verification)
- We find a prevalence of context features. E.g. in A/4, there are over a hundred features which respond to the token “the” in different contexts.
- We see “feature splitting”, where features happen in clusters. The 100 types of “the” would appear in a cluster. This shows that the hypothesis in “Toy Models of Superposition” misses something.

Key findings
Dictionary learning lets us extract features that are significantly more monosemantic. Features respond to Arabic script, DNA sequences, base64 strings, and Hebrew script.
- Each learned feature activates with high specificity and sensitivity for the hypothesises context (Arabic script is present).
- The feature causes appropriate downstream behaviour.
- The feature does not correspond to any neuron.
- The feature is universal, so it can be found by applying dictionary learning to another model.