Link to the paper: https://transformer-circuits.pub/2022/toy_model/index.html#demonstrating-setup-loss If you have more time, Neel’s video is super helpful!
Basically: “Why do models have more features than they have dimensions? That’s weird, let’s build a toy model to figure this out!”
Turns out, models compress all these features in a process called superposition
Polysemanticity
A model sometimes uses a single neuron to represent a single feature (monosemanticity). E.g. a Trump neuron, or a holiday neuron, which fires when the model thinks this feature is being represented. However, this is not always true.
Sometimes we see a neuron activate for cat’s legs AND cars. This is weird, since these two things have nothing to do with each other! This is called polysemanticity.
Superposition
- Superposition is where models represent more features than they have dimensions. These features are compressed into lower dimensions when features are sparse.
- A good intuition is that the NNs we observe, given a lot of features it wants to represent but not enough dimensions, essentially mimic/simulate larger, highly sparse networks.
- Toy model here refers to small ReLu networks trained with sparse input features.
Feature importance and sparsity
The model has a tradeoff between representing more features and having less interference.
E.g. a toy model with 2 dimensions and 5 features.
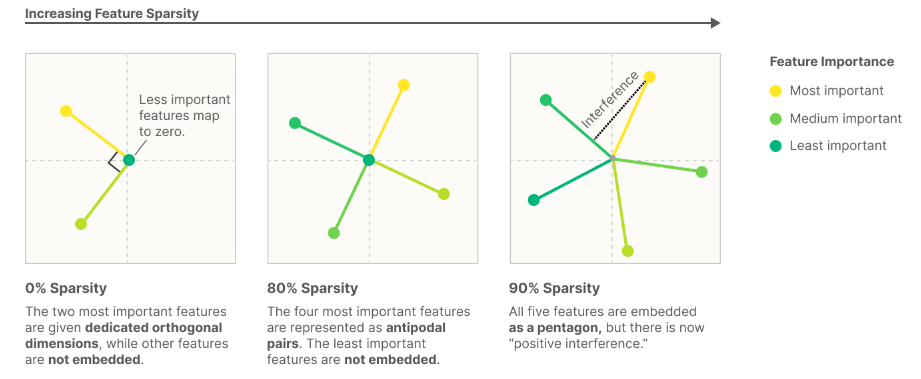
Notice how the features are sometimes represented orthogonally, somewhat orthogonally, and just spaced out. There are two factors that matter in the positioning of features.
Feature importance represents how important it is for a model to represent a feature. It makes sense that for an LLM, representing the language the text is written in is much more important/useful to represent than representing the word “rearview”. In this toy model, importance is just a loss function.
Intuitively, the more important a feature is, the less interference with other features you want.
Sparsity is how many features are present at a given time. Sparse features are features that don’t show up that often, such as the feature of detecting blue scales on a dragon and the feature of the tennis player Mirra Andreeva. The sparse features allows models to superposition features (since they are not all needed at once very often).
This explains why neurons are sometimes monosemantic and sometimes polysemantic (the number of features they try to represent in superposition)
Here are two intuitions for understanding features:
- Features are interpretable properties and concepts that are strikingly understandable to humans
- Features are neurons in sufficiently large models
The linear representation hypothesis:
- Decomposability: Network representations are described completely through independent features
- Linearity: Features are represented by direction